Sitede Gömülü PDF Ya Da JPG Nasıl İndirilir 2
-
idm nin toplu indir bölümünü de kullanabilirsin.
yNsr tarafından 07/Eki/22 20:02 tarihinde düzenlenmiştir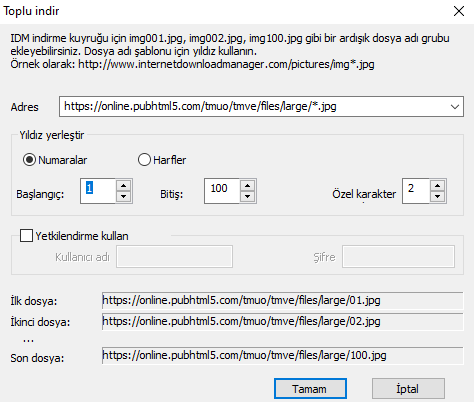
-
import requests import re import json from os.path import realpath, dirname, exists from os import makedirs from shutil import rmtree from PIL import Image BASE_PATH = dirname(realpath(__file__)) def download(path, url): try: client = requests.get(url, allow_redirects = True) with open(path, 'wb+') as image: image.write(client.content) except Exception: download(path, url) def convert(inputSequence, outputDir): images = [(Image.open(input)).convert('RGB') for input in inputSequence] images[0].save(f'{outputDir}.pdf', save_all=True, append_images=images[1:]) def getBookList(url): client = requests.get(url) match = re.findall(r'bookData:\s(.*?)[\s]+}', client.text)[0] return json.loads(match) bookList = getBookList('https://pubhtml5.com/bookcase/dofw') for book in bookList: title = book['title'] totalPageCount = int(book['pages']) pageSeq = range(1, totalPageCount+1) baseUrl = book['url'] pages = [f'{baseUrl}files/large/{page}.jpg' for page in pageSeq] tmpSavePath = f'{BASE_PATH}/tmp/{title}' not exists(tmpSavePath) and makedirs(tmpSavePath) for pageNum, pageUrl in enumerate(pages): download(f'{tmpSavePath}/{pageNum+1}.jpg', pageUrl) convert([f'{tmpSavePath}/{page}.jpg' for page in pageSeq], f'{BASE_PATH}/{title}') rmtree(tmpSavePath) print(f'{title} ({totalPageCount} sf.) basariyla indirildi!')https://gist.github.com/gokaybiz/0d1b1caaeb0d036e5abb05ff79225d47
hizlica yazdim, multi threading icin ugrasan olursa cok guzel olur.
pyinquirer ya da basit bir while loop ile secmeli de yapilabilir, bu haliyle butun kitaplari indiriyor
end tarafından 08/Eki/22 02:15 tarihinde düzenlenmiştir -
yNsr bunu yazdı
idm nin toplu indir bölümünü de kullanabilirsin.
Ben IDM Grabber önermeye gelmiştim bu çok daha basit versiyonuymuş ve çohoşuma gitti güzelmiş


