
C# - T-Sql Gecmis Olusturma
-
Arkadaslar,
Bir proje ustunde calisiyorum. Bu projede yapilan islerle ilgili tum kayitlari tutmaktayim ve sadece islerle ilgili kayitlar 10 civarinda tabloda yer almakta. Projenin sonlarina geldim.
Fakat "gecmis" (history) olusturmakla ilgili bir problemim var. Simdi ben bitmis olan isleri bir sekilde gecmise atmak istiyorum. Aksi halde 4-5 sene sonra cok agir gitmeye baslayacak gibi. Cunku mesela sadece bir modulde 10 a yakin tablodan join yapiyorum ve isler gecmise atilmazsa bitmis olan isleride yukleyecegi icin sikinti olacagini dusunuyorum.
Ilk aklima gelen atiyorum ( jobs , jobs_records v.s. ) tablolarim var ve bunlar icin history_jobs , history jobs_records tablolari olusturup isler bittiginde buralara tasimak. Fakat bu sefer bazi modullere geri donup (history) secenegi eklemem gerek. Aksi halde isler hic yokmus gibi davranacak.
Ikinci aklima gelen ise tablolara _in_history column'u ekleyip oradan yurumek. Ki bu daha hizli sonuca ulastiriyor. Ve gordugum kadariyla where in_history <> '1' deyince hizli calisiyor queryler.
Sizin oneriniz nedir ? Baska fikri olan ?
Tesekkurler
-
hocam projedeki joblarin aktiflik surecleri neler ?
su yuzden soruyorum ki mesela payment_printjob_2016 gibi bir tablom var. 2017 ye gecince bunlari otomatik olarak 2017 tablosundan aliyor olacagim. Eger 2016 icindeki islerim var ise bunlari da devir statusune cekip 2017 nin basinda tekrardan insert ediyor olacagim.
-
selam hocam,
aslında cevabı kendin vermişsin..
veritabanındaki tabloda ne kadar çok veri olup olmadığından bunları çekip çekmemen daha önemlidir.
En sonda bahsettiğin _in_history column kolonunun bit türüne bir değer vererek (1 ve 0) bunun history e gidip gitmediğini ayarlayabilirsin.
Dikkat etmen gereken şey ise join. Maalesef bir çok insan önce tüm tabloyu birleştiriyor daha sonra where ile şart yazıyor. Halbu ki önce tabloları eleyip alias ile sahte isimli tablolar oluşturup bunları joinlese performans ciddi manada artar.
Demem o ki; iki tabloyu direk joinlemek yerine, tablolarda gereksiz kayıtları atıp joinlemek gerekiyor.
İki tip sorgu planı vardır.
1- Logical Query Plan
2- Physical Query Plan
bunları biraz araştırabilirsin.
Join lere gelince de 3 tip join mevcut
1- Hash join
2- Nested loop join
3- sort-merge join
bunların da kendilerine göre cost ları vardır. Araştırabilirsin.
Where conditionlarda performans sağlamak için clustured ile ilerlemek lazım (name yerine id ile sorgulama gibi..)
şimdi bizim hocanın slaytlaından bir kaç örnekleri ekleyeyim..
aşağıdaki resimde örnek bi tane sorgu var. Burada tüm tablolar alınıyor ve sno ile joinleniyor daha sonra iki şart ile seçilme işlemi yapılıyor. Bu genelde yapılan sorgulama türü ve cost u gördüğün gibi 10100 (belirli sayıda veriler için)
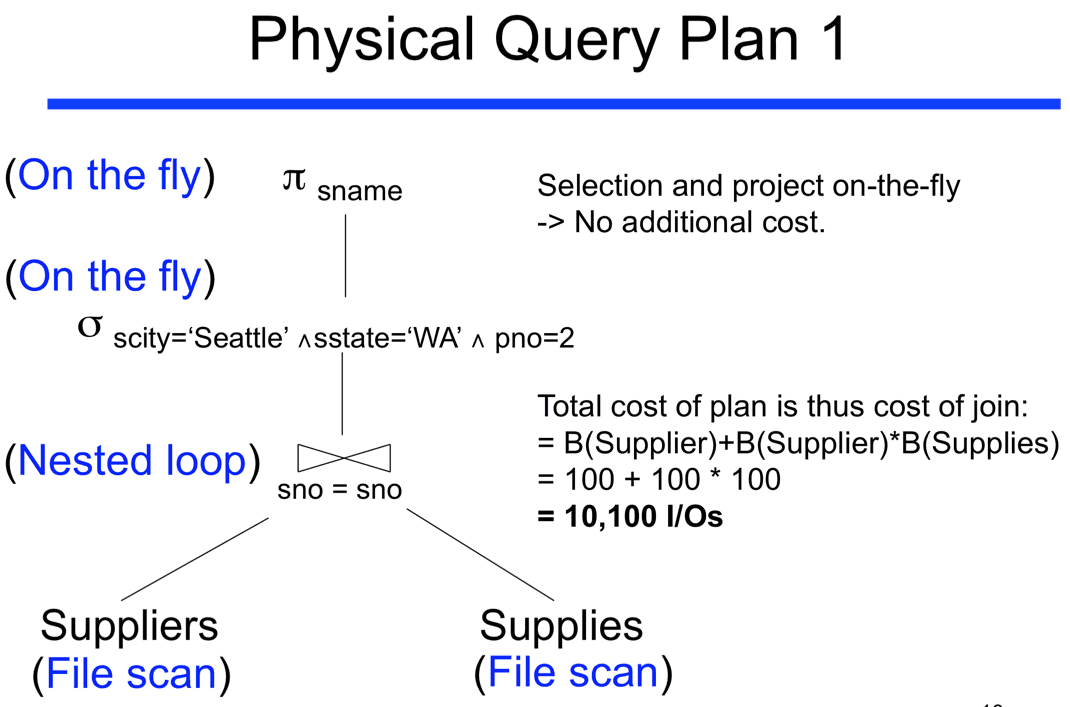
ikinci resime bakalım, burada ise benim dediğim gibi öncelikle tüm tablolardan ayrı ayrı uygun veriler seçiliyor (üstte anlattım her tablo için where ile öncelikle ayıklama yapmak lazım), daha sonra kalan veriler joinlenir. Üstteki tablo ile aynı veri sayısına sahip, bunun da cost u gördüğün gibi 204

İkisi arasındaki farkı görüyor musun :)
Tabi işlem burada bitmiyor, eğer daha çok veri eklenirse bu sefer bu mantık da çok performanslı olmayabilir o zaman da indexleme devreye girecek ama bu baya ileri konu.. Araştırmak istersen bakabilirsin.
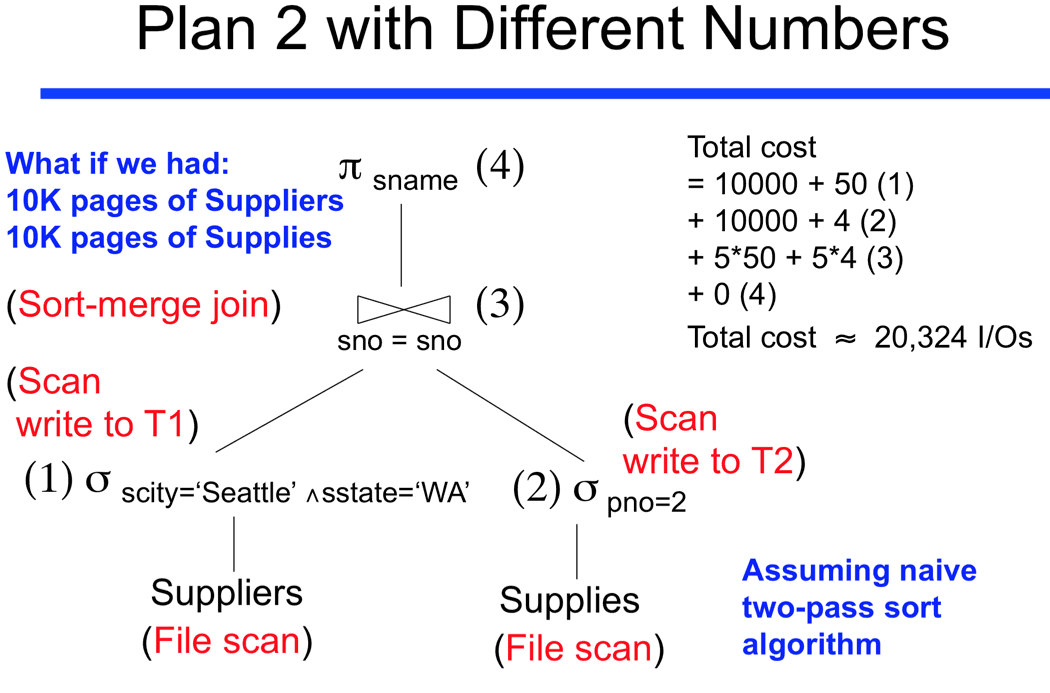
3. resimde daha fazla veri ile çalışıyor..
Üstteki aynı mantık ile gidilse dahi cost u 20 binden fazla çıkıyor, çünkü çok daha fazla veri var..
Bu costu da düşürmek için hash-index tabanlı olarak datalar seçiliyor (clustured olduğuna dikkat et), daha sonra tipik join işlemi yapılıyor ve cost o kadar veri için sadece 7 ye düşüyor.
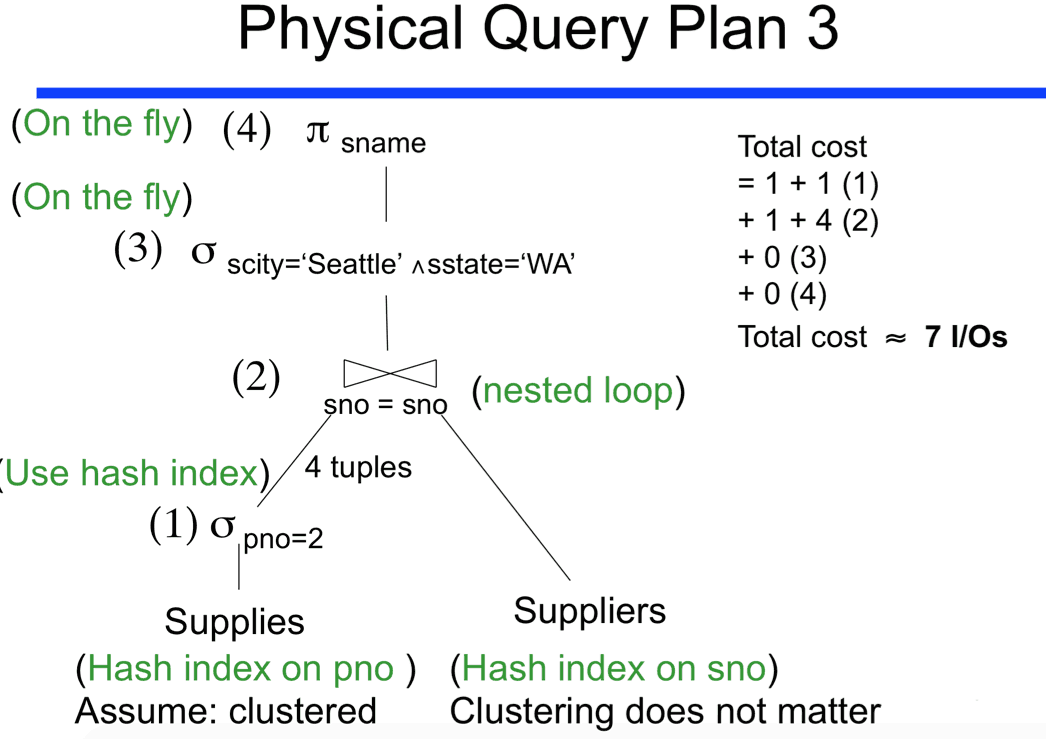
Sql de indexleme, clustering kavramları çok önemli ve veritabanı sorgularında performansı direk etkileyen faktörler aslında bunlardır.
Son resmi biraz daha açayım, sol taraftaki tabloda uygun 4 tane veri geliyor, sağ taraftaki tabloda ise bir sürü veri gerebilir. Ama bu tarz sorgularda tüm tabloların alınıp da join yapılması mantıklı değil. O yüzden mümkün mertebe verileri azaltmak gerekiyor. Ancak en sondaki resimde 4 tane kayıt dönmüş, o sebeple sağdaki tabloda her hangi bir seçim işlemi yaptırılmıyor, onu birleştirmeden sonraya almış çünkü birleştikten sonra fazla veri olmuyor. Bu da 3. resimdeki gibi yapmanın gereksizliğini gösteriyor.
Üst taraflarda yazdığım gibi bunlar sorgu planları. Kendi tablolarının yapılarına, içindeki verilerine göre bu tarz planlar çıkarıp en uygunu neyse ona göre hareket etmelisin.
Umarım yol gösterebilmişimdir,
Kolay gelsin
-
Datan çok büyüyecek ve searching algoritmaların varsa, ayrı tabloda tutmak daha mantıklı ama bu sefer de join' lerden sorgu yazmak çok zorlaşacak.
Data çok büyümeyecekse aynı tabloda column ekleyerek kolay çözüm sağlanabilir.
-
çizik
-
unbalanced bunu yazdı
selam hocam,
(...)
Kolay gelsin
Sagolasin unbalanced.
Mumkunu varsa hocanin slaytini ( tabi sikinti olmayacaksa senin icin) atar misin ?




