
UTF-8 Ve UTF-16 Nın Bellekteki Bitsel Organizasyonu.
-
Arkadaşlar bugünlerde aklıma takıldı takıldı durdu. Konuyuda nereye açayım bilemedim. PHP yede ASP.net de C# da acabilirdim ama c++ daha uygun olur diye düşündüm.
Şimdi gelelim konumuza. UTF-8 in bellekteki bitsel organizasyonu nasıl oluyor.
Mesela ascii sistemde char bellekte 1 byte yer kaplıyor ve A harfinin karşılığı tam sayı olarak 65 saysıdır.
UTF-8 sisteminde bellekte kapladığı alan kaç ve örnek olarak büyük A harfinin karşılığı ne oluyor.
Umarım açıklayabilmişimdir.
Teşekkürler.
-
şöyle bir tablo var ama soruna cevap olur inşallah
(kaynak: http://www.icu-project.org/docs/papers/forms_of_unicode/)
UTF Formats Estimated average storage required per page (3000 characters) UTF-8 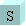



3 KB
(1999)
5 KB
(2003)On average, English takes slightly over one unit per code point. Most Latin-script languages take about 1.1 bytes. Greek, Russian, Arabic and Hebrew take about 1.7 bytes, and most others (including Japanese, Chinese, Korean and Hindi) take about 3 bytes. Characters in surrogate space take 4 bytes, but as a proportion of all world text they will always be very rare. UTF-16 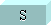

6 KB All of the most common characters in use for all modern writing systems are already represented with 2 bytes. Characters in surrogate space take 4 bytes, but as a proportion of all world text they will always be very rare. UTF-32 
12 KB All take 4 bytes -
yok usta sorduğum soru o değil. Ve bir sorum daha var. UTF-8 de 8bit lik yer işgal ediliyor yani 1 byte. Ama gelelim görelim ki 1 byte normalden unsgined olarak en fazla 255 karakter tanımlayabiliriz. E nasıl oluyorda bu UTF-8 de binlerce karakter tanımlanabiliyor.
-
usta bi de şu linke bak istersen belki anlarsın ben o kadar bilgi sahibi değilim ama hissettim ki bu linkten sen bi şeyler çıkarabilirsin :D
http://www.fileformat.info/info/unicode/utf8.htm
-
utf-8, 1 ile 4 byte arasinda degisir, tanimlanan karaktere gore degisir, tek bytelik kullanim geriye uyumluluk acisindan ASCII kodlarini temsil eder..kapladigi alan acisindan avantaj saglar, ustelik cince sivelerden, misir hiyeroglif alfabesine kadar bircok sembolu ifade etmek mumkundur.
-
tmmdır beyler şimdi kavradım olayı yalnız madem bu kadar kapsamlı ve 4 byte a kadar çıkabiliyor utf-16 utf-32 nin temsilasyon sebebi nedir ve kapaldığı alan bakımından utf-8 den farkı nedir?
-
tahminen yazıyorum :D mesela utf-32 kullanılırsa A yazmak için de 4 byte kullanılır fakat A yazmak için 1 byte yeterlidir. ama utf32'de karışıklık ve hatalar daha az olur gibi geliyor bana arama yaparken falan utf8 de 4 byte için 4 adet 1 baytlık seri kullanılıyor bunlar karışabilir, utf32de her bir karakteri tek bir 4bytlık veriyle temsil ettiğimizden hepsi kendine özgü olur.
şimdi yazdığım yazıyı okuyunca ben de karışık buldum biraz :D tamamen sallamış da olabilirm


