
Bot Savaşları
-
Herkese selam,
Geçenlerde botlar hakkında dönen bir muhabbet üstüne bir test yapalım dedik, @FCN @wasd ve ben çeşitli dillerde farklı araçlarla ufak botlar yazdık. Testini yaptık, konuyu açmak farz oldu tabi.
- Botlar C#, Python ve PHP ile yazıldı. @FCN C# ile bir tane HtmlAgilityPack kullanan, bir tane de düz regex kullanan bot yazdı. Ben Pythonda Scrapy, lxml ve beautifulsoup modüllerini kullanarak 3 ayrı bot yazdım. (@0xüçbeşbişey de bir şeyler yapacaktı güya, neyse ) @wasd ise PHP'de curl ve SimpleHtmlDom kütüphanesini kullanarak yazdı.
- Botlara verilen görev http://www.tahribat.com/Forum/ sayfasındaki link sayısını bulmaktı.
- C# ile yazılan botlar Windows 10'da, PHP ve Python ile yazılan botlar yine aynı bilgisayarda Ubuntu 14.04'de tarafımca test edildi. İnternet bağlantısının stabilliği tartışmaya açık olmakla beraber sonuca daha gerçekçi yaklaşabilmek için her bir bot 10 kere test edildi ve ortalamaları alındı.
- Python ile yazılan botlar Linux'teki time komutuyla test edilip, çıkan sonuçtaki real time değeri alındı. C# ve PHP ile yazılan botlarda hesaplama programın kendi içinde yapıldı.
PYTHON
Lxml:
import requests from lxml import html url = 'http://www.tahribat.com/Forum/' xpath = '//a/@href' page = requests.get(url) tree = html.fromstring(page.text) print(len(tree.xpath(xpath)))
Beautifulsoup:
import requests from bs4 import BeautifulSoup def get_links(url): response = requests.get(url) soup = BeautifulSoup(response.content,'lxml') c = len(soup.find_all('a')) print(c) get_links("http://www.tahribat.com/Forum/")Scrapy:
import scrapy,os class TBTCrawler(scrapy.Spider): name = 'tbt' start_urls = ['http://www.tahribat.com/Forum/'] def parse(self, response): c = len(response.css('a').xpath('@href')) print(c) if __name__ == "__main__": com = 'scrapy runspider "%s"' % __file__ os.system(com)C#:
HtmlAgilityPack ve Regexle yapılan botlar tek program içinde, kodlar yaklaşık 80 satır o yüzden pastebin linki veriyorum: http://pastebin.com/u7L7RRUH
PHP:
Bot.php:
<?php header("Content-Type: text/html; charset=utf-8"); require_once 'shd.php'; function getSite($site) { $ch = curl_init($site); $hc = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36"; curl_setopt($ch, CURLOPT_REFERER, 'http://www.google.com'); curl_setopt($ch, CURLOPT_USERAGENT, $hc); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); $site = curl_exec($ch); curl_close($ch); return $site; } $baslama = microtime(true); $data = getSite('http://www.tahribat.com/Forum/'); $sayfa = str_get_html($data); echo "URL sayısı: ".count($sayfa->find('a'))."<br>"; $toplamSure = microtime(true) - $baslama; echo "Çalışma süresi: ".$toplamSure; ?>Çalıştırmak için gereken SimpleHtmlDom kütüphanesi: http://pastebin.com/GqFCXqjJ
SONUÇLAR:
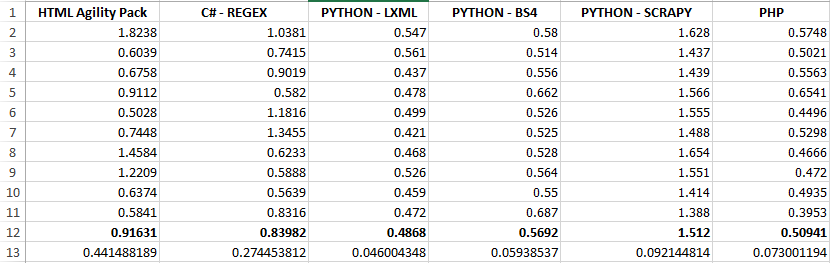
(12. satırda 10 sonucun ortalamaları, 13. satırda değerlerin standart sapması belirtilmiştir.)
10 testin ortalamasına baktığımızda,
- Pythonda Lxml ile yazılan botun ortalama 0.4868 saniyede verilen linkleri sayması ve yaklaşık 0.04lük standart sapmasıyla en başarılı bot olduğunu,
- Yine Pythonda Scrapy ile yazılan botun ortalama 1.512 saniyede verilen linkleri saymasıyla en başarısız bot olduğunugörebiliyoruz.
Sıralama şu şekilde olmaktadır: 1- Lxml(Python) 2- PHP 3- BeautifulSoup (Python) 4- Düz Regex (C#) 5-HtmlAgilityPack (C#) 6-Scrapy (Python)
NOTLAR VE YORUMLAR- Sonuçlarda Python ile yazılanların time komutu ile diğerlerinin de program içinden süre tutmasının etkisinin olabileceği ihtimalini es geçmemek gerekir.
- Scrapy gerçekten crawling işlemleri için yapılmış bir modüldür ve yüzlerce hatta daha fazla sayıda sayfaları çok hızlı taradığı bilinmektedir. Bu testte sonuncu olmasının sebebi ise diğerlerine göre başlangıçta daha fazla process yönetmesiyle ve/veya bu test için yapılan örnekte gereksiz kodlar bulunabilmesiyle alakalı olabileceğini de es geçmemek gerekir.
- Sonuçlarda, testlerin bir kısmının farklı zamanlarda ve farklı işletim sistemlerinde yapılmış olmasının ve yeterince stabil olmayan kablosuz internet bağlantısının etkisinin olabileceğini es geçmemek gerekir.İsteyenlerin farklı dillerle, farklı araçlarla veya farklı yöntemlerle örnekler hazırlayıp katkıda bulunmasını memnuniyetle karşılarız.
-
Niye herkes bana 0x bilmem ne diyor küfür ederim bak :/
İşin içinde çok fazla değişken var internet bağlantısı vs vs
BS4 de aslında css selector olarak kullansaydın daha iyi değil miydi ? find_all ile zaten bi nevi xpath yani
Not :Bu arada aktif olarak görev alamamın sebebi tatilde olmam ve telefonla ne yazayım ? :D ( Yazmasına yazılır da üşenirim )
0x656e tarafından 17/Eyl/16 21:22 tarihinde düzenlenmiştir -
Ne güzel iş yapmışsınız bir bilim adamı edası ile. Gözlemler falan:)
-
0x656e bunu yazdı
Niye herkes bana 0x bilmem ne diyor küfür ederim bak :/
İşin içinde çok fazla değişken var internet bağlantısı vs vs
BS4 de aslında css selector olarak kullansaydın daha iyi değil miydi ? find_all ile zaten bi nevi xpath yani
Not :Bu arada aktif olarak görev alamamın sebebi tatilde olmam ve telefonla ne yazayım ? :D ( Yazmasına yazılır da üşenirim )Bs4 te default olarak lxml kullanılıyor aslında, test yaparken konsolda uyarı veriyordu "Bak default olarak lxml kullanıyorum şu an, eğer bu uyarıyı görmek istemiyorsan kodda da belirt." diye. O nedenle lxml olarak belirttim.
Scrapy de parse işlemleri için lxml kullanıyor olabilir emin değilim ama.
Farklı varyasyondaki botları da sizden bekleriz efendim :D
-
test yanlış
scrapy'nin load süresini gözardı edersen "çok geç indirip parse ediyor yhaa" dersin böyle
ayrıca 2 defa find çektirerek süreci yavaşlatmışsın, '//a/@href' xpath'i dururken
maksat requests + linkleri buldurma süresi ise, doğru kod:
https://gist.github.com/anonymous/b41b2b4407b53185e9694882d538b49d
scrapy'yi düzgün kullandığında diğerlerinin sunmadığı avantajları ve performansı elde edersin
hadi kolay gele
-
YekteranBaymedir bunu yazdı
test yanlış
scrapy'nin load süresini gözardı edersen "çok geç indirip parse ediyor yhaa" dersin böyle
ayrıca 2 defa find çektirerek süreci yavaşlatmışsın, '//a/@href' xpath'i dururken
maksat requests + linkleri buldurma süresi ise, doğru kod:
https://gist.github.com/anonymous/b41b2b4407b53185e9694882d538b49d
scrapy'yi düzgün kullandığında diğerlerinin sunmadığı avantajları ve performansı elde edersin
hadi kolay gele
tişikkirlir sipirmin
-
Süper bir çalışma.
-
Bu test ile ilgili sıkıntılar var, açıklayayım.
Denek güvenilir değil, yani tahribat. İlla dinamik bir yanıt işlenecekse veya bu aralar pek de güvenilir olmayan tahribat gibi bir site test edilecekse 10 yeterli bir istek sayısı değil. Birkaç yüzden aşağı olmamalı.
Ben hatrı sayılır bir DOM ağacına sahip olan statik ama uzak bir dosya ile yapmayı yeğlerim.
Scrapy diğer kodlara denk değil. Arada çok fazla (alameti farikası bu) middleware var. Buradan kendisine saygılarımızı iletelim.
DOM ağacı oluşturup sunan kod ile Regex'i eşleşmesi yapan kodlar da "Scrapy ve diğerleri" gibi denk değil.
PHP ve C# kodlarında sıkıştırılmış yanıt kabul edileceği belirtilmemiş. Haliyle sıkıştırılmamış, daha büyük bir yanıtı beklemek zorundalar. 110 KB civarı trafik oluşturuyorlar.
Python'un requests'inde sıkıştırma varsayılan olarak açık, 14 KB civarı trafik oluşturuyor.
buzukatak tarafından 17/Eyl/16 22:30 tarihinde düzenlenmiştir -
Php de curl ile kod çekmek pekte mantıklı gelmiyor bana , bununla beraber 19.satırda tekrar str_get_html e atanması na da gerek yok ; aşağıdaki kodları da bi teste tabi tut istersen benim pc de daha verimli çıktı
function UrlSay($url) { $opts = array( 'http'=>array( // 'method'=>"GET", 'header'=>"User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36" ) ); $context = stream_context_create($opts); $kodal = file_get_html($url,false,$context); echo count($kodal->find('a')); } -
Güzel konu olmuş, varmı farklı bir yöntemle daha hızlı çektiririm diyen
-
coder2 bunu yazdı
Php de curl ile kod çekmek pekte mantıklı gelmiyor bana , bununla beraber 19.satırda tekrar str_get_html e atanması na da gerek yok ; aşağıdaki kodları da bi teste tabi tut istersen benim pc de daha verimli çıktı
function UrlSay($url) { $opts = array( 'http'=>array( // 'method'=>"GET", 'header'=>"User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36" ) ); $context = stream_context_create($opts); $kodal = file_get_html($url,false,$context); echo count($kodal->find('a')); }file_get_html ile çekersen sıkıntı yok, ama str_get_html string ile çalışıyor url ile değil. Php gurusu değilim zaten, kimse php ile yazmak istemedi ben yazayım dedim :D curl ile data çekmek neden mantıklı değil?







