
Openmp Ve MPI İle İlgili Turkce Kaynak Nerden Bulabilirim ?
-
Hemen yolliyim elimdeki Herseyide Nasil ? Nerden onu Bilmiyorum uzun Zamandan Sonra Yeniden Tarikattayım :)
-
Hoşgeldin öncelikle. Elindeki dosyaları bir araya getirip rapidshare ya da benzeri herhangi bir siteye upload edip, download linkini bu konu altına yazabilirsin.
-
Birde bendeki Projeler Matrisleri Hesaplıyo Kac ıslemcıyle ne Kadar Da Hesaplandıgını.
-
http://rapidshare.com/files/362406732/OpenMP_MPI.rar.html
bulabıldıklerım Bunlar :) -
http://rapidshare.com/files/362423219/ppmpi_c.rar.html
al hocam bunlarda bizim ünideki örnek kodlar daha ileri konuların örnek kodlarıda var belki yardımcı olur.
-
Ben bulduklarimi direkt yazili olarak paylasiyorum cunku koyulan linkler siliniyor genelde! Umarim anlamaniza yardimci olur.
MPI ile Paralel Programlama
Paralel programlamayı herkes duymuştur ama çok az insan kullanmıştır. Paralel programlamanın az kullanılmasının sebebi paralel makinelerin pahalı olması kontrolünün zor olması ve en önemlisi de genel olarak ihtiyacımızın olmamasıdır. Peki paralel hesaplamalar nerede kullanılmaktadır? Araştırma laboratuarları, üniversiteler, ileri teknoloji kullanan şirketler limitlerinin zorlandığı durumlarda paralel makinelere ihtiyaç duymaktadırlar. Örnek olarak Koç Üniversitesinde “moleküler simülasyonlar”, “quantum computing”, ”computational electromagnetics”, ”bioinformatics” ve benim de uğraştığım “computational flow simulation/modelling” gibi değişik araştırma projeleri üzerinde uğraşılmaktadır. Bu paralel hesaplamalar için de MPI adı verilen Message Passing Interface adlı paralel işlem kütüphanelerini (Library) kullanmaktayız. Bunun dışında değişik kütüphaneler de vardır.
Donanım / Yazılım
Donanım olarak en basit makineleri birbirine bağlayarak bile bir cluster elde edebilirsiniz. Bunun için bilgisayarınıza gerekli MPI (Message Passing Interface – Paralel kütüphaneler başka standartlar da var ben MPI kullanıyorum) dosyalarını ve bazı programları kurmanız gerekmektedir. Bunlardan bir tanesi openPBS (Open Portable Batch System ) iş akışını düzenlemektedir ve OSCAR adlı ( MPI,SSH,SSL,MPICH,... gibi gerekli kütüphaneleri, programları bize sağlamaktadır ) programdır. Her ne kadar işletim sistemi olarak unix/linux tabanlı işletim sistemleri desteklense de windows tabanlı işletim sistemleri için de bu yazılımların versiyonları vardır. Donanım olarak bütün işlemciler desteklenmektedir (Windows işletim sistemlerinde bu destek yoktur). Ayrıca ULAKBIM den (128 node’ luk güzel bir clusterları var) account almanız mümkün, tabi akademik amaçlar için kullanacağınıza ikna etmeniz gerekecektir. Yine de account alamaz ve test etmek istediğiniz bir kod olursa bana yollarsanız ben deneyebilirim.
MPI nedir?
Kısaca bahsettik ama MPI nedir? Nasıl çalışır? Başka makinelere/cpu’ lara nasıl sonuç yollar... Biraz bunlardan bahsedelim. Öncelikle yazdığınız her paralel kodun başına “mpi.h” headerini eklemeniz gerekmektedir. Bu header dışında kullanmanız gereken başka header yoktur. MPI fonksiyonları makineler arası iletişimi, işlem önceliklerini, yük ayarını vs düzenlemektedir.Format olarak MPI fonksiyonları MPI_Xxxxx(parameter, ... ) formatını kullanmaktadır. MPI fonksiyonlarını size kısaca tanıtayım:
MPI_Init(&argc,&argv)
MPI_Init fonksiyonunu bütün kodlarınıza eklemeniz gerekmektedir. MPI_Init fonksiyonuna komut satırından da parametre verebilirsiniz ama mecbur değilsiniz. MPI_Init size bir değer dönmektedir bu “MPI_SUCCESS” olursa kod geri kalan MPI_X fonksiyonlarını kullanabilecektir, eğer bu değer dönmezse MPI_X fonksiyonlarını kullanamazsınız.
MPI_Comm_size(comm,&size)
Bu fonksiyonumuz proses sayısını bize vermektedir. Genellikle “comm” kısmına MPI_COMM_WORLD üst fonksiyonu yazılmaktadır.
MPI_Comm_rank(comm,&rank)
Bu MPI fonksiyonu çağıran prosesin sırasını vermektedir. Başlangıçta bütün prosesler 0 veya -1 değerlerini almaktadır. Daha sonra MPI tarafından sıraya sokulunca bütün prosesler numaralandırılmaktadır. Aşağıda ki örneğimizde göreceğimiz gibi makineler 0 dan başlayarak rank(sıra) alacaklardır.
MPI_Abort (comm,errorcode)
Adından da anlaşıldığı gibi bütün prosesleri durdurmaktadır. Istenmeyen durumlarda başvurulabilecek bir fonksiyondur.
MPI_Get_processor_name(&name,&resultlength)
İşlemcinin adını ve adın uzunluğunu dönmektedir.
MPI_Initialized(&flag)
MPI_Init fonksiyonun çağırılıp çağırılmadığını kontrol etmektedir ve çağırıldıysa “1” dönmektedir. MPI_Init her proses tarafından sadece bir kere çağırılması gerektiği için MPI_Initialized fonksiyonu olası çakışmaları önlemektedir.
MPI_Wtime( )
Double deger olarak paralel kodun çalışmaya başlamasından sonra geçen zamanı vermektedir.
MPI_Finalize( )
Bütün işlemlerimizden sonra MPI_Finalize diyerek işlemlerimizi sonlandırıyoruz.
Yukarıda gördüğünüz fonksiyonlar genel MPI fonksiyonlarıdır ve sadece kodunuzu yönetmek amacıyla kullanılmaktadır. Bunların dışında 100’ e yakın daha fonksiyon vardır. Onlara gelecek yazılarımızda değinmeye çalışacağız.
Hello World 0 Hello World 1 Hello World 2 ....
Şimdi geldik kod kısmına! Klasikleşmiş “merhaba dünya” örneğimizi bu sefer paralel bilgisayarlarda uygulayacağız. Her bilgisayardan selamlama mesajı göndereceğiz. Bunun için yukarıda açıkladığımız fonksiyonları kullanacağız.
HTML-Kodu:
#include
#include "mpi.h"
int main( argc, argv )
int argc;
char **argv;
{
int rank, size;
MPI_Init( &argc, &argv );
MPI_Comm_size( MPI_COMM_WORLD, &size );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
// beklemek istemediğim için fprintf komutu ile myout.dat dosyasına yazdırıyorum
printf( “Hello world from process %d of %d \n", rank,size);
MPI_Finalize();
return 0;
}
Compile edip çalıştırınca cevap olarak aşağıdaki ekranı görmekteyiz.
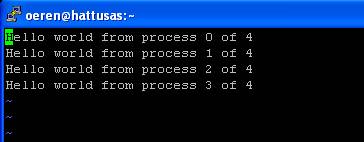
Haklı olarak “sadece bir tane proses gözüküyor” diyeceksiniz. Hatamız burada paralel işlem yapacak bir kodu normal bir C kodunu çalıştırdığımız gibi çalıştırmamızdır. Bunun için paralel makineye iş yüklemek gerekmektedir (işin bu kısmı genelde hiç söylenmez). Bunun için PBS yazılımının manuelinden nasıl komut aldığına bakıyoruz (scriptteki #PBS bu bahsettiğimiz komutlardır). Örnek olarak yüklediğimiz işe isim vermek istersek #PBS N benim işim diyebiliyoruz. Oluşacak output ve error bilgileri için log dosyaları da oluşturabiliriz. Daha sonra bu yazdığımız 10-15 komutu bir defada çalıştırmak için bir job script yazıyoruz. Bu yazıda amacımız linux öğretmek olmadığı için bunları detaylı olarak açıklamayacağım. Yukarıda bahsettiğim PBS adlı program sizin verdiğiniz komutları değerlendirerek bilgisayarların iş yoğunluğuna göre verilen işleri sıraya sokmaktadır ve ona göre cpu, hard disk, memory tahsisi yapmaktadır. Size bu iş için yazdığım job scripti göstereyim. Aşağıda gördüğünüz ### comment yani yorumlar, geri kalan kısımlar execute edilecek komutlardır.Yazımın sonunda size daha kestirme bir yoldan da bahsedeceğim ama o yöntem sistem admini tarafından görülürse hiç hoş karşılanmayan bir durumdur (ki genelde serverlerde sizin ana makineye PBS aracılığı ile iş yüklemeniz dışında kolay kolay komut kullanamazsınız).
HTML-Kodu:
#!/bin/sh
### iş ismi “ozkanen” ismi verdim
#PBS -N ozkanen
### Output files
### olusacak output ve olusacak error loglarını buraya koyabiliriz
#PBS -o ozkanen.out
#PBS -e ozkanen.err
### Buraya dikkat edin!!!
### 4 gördüğünüz kısım 4 makine kullanacağım demek
### 1 gördüğünüz kısım 1 makinede 1 işlemci kullanacağım demek (hattusas da her node da bir işlemci var)
#PBS -l nodes=4:ppn=1
### programın ne kadar çalışacağını söylemektedir
#PBS -l cput=32:00:00
#PBS -l walltime=32:00:00
### Queue name
### clusteri paralel olarak kullanacagim icin asagidaki kodu yazıyorum
### clusterları isterseniz tek tek de kullanabilirsiniz
#PBS -q parallel
#PBS -m abe
### cevap cıkınca bana mail at demek oluyor aşağıda
#PBS -M oeren@ku.edu.tr
### Script Commands
### aşağı kısımlar o kadar önemli değil sadece size işlerin çalıştığını ve nerede çalıştığını size söylüyor
cd $PBS_O_WORKDIR
echo "Running test"
echo ’group main’ > machines
cat $PBS_NODEFILE | awk ’{print "host " $1}’ >> machines
echo ’current directory is’
pwd
echo ’Running test’
### aşağıda ./hello adını verdiğimiz dosyayı çalıştırıyoruz
### istersek cevapları output dosyamıza yazdırabiliriz
./hello out
### işimiz bittiği zaman bize bittiğini haber vermektedir
echo "job complete"
exit 0
Bu job scripti yazdıktan sonra oerentest.job ismi ile kaydediyorum. Çalıştırmak için de qsub oerentest.job diyorum.
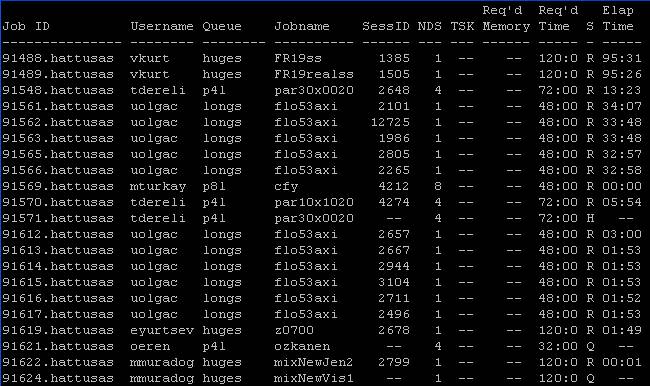
a komutu yazdığım zaman ekranda 91621 kodu ile işimin sisteme girildiğini görüyorum. Status anlamına gelen S sütunundan yüklediğim işimin Q (yani sırada olduğunu) durumunda olduğunu görüyorum. Kodum saniyelik bir run yapıp bana cevap verecek ama yukarıda gördüğünüz gibi sıra olduğu için PBS sıraya sokuyor (32 node da olsa her zaman fazla iş var). Eğer dikkatlice bakarsanız NDS de 4”yazdığını görürsünüz bu 4 tane makine istiyorum anlamındadır, ayrıca ben dahil kimse memory’ den kısıtlama yapmadığı için Req memory kısmı boş gözükmektedir. Ayrıca Req Time sütununa bakarsanız 32 saatlik bir iş verdiğimi ve Elap Time sütununa bakarsanız hiç çalışmadığını göreceksiniz. Bayağı uzun sürdüğü için ben bu işimi bir output dosyama yazdırıp sonraya bırakıyorum ve filmimi seyrediyorum. Aradan bayağı bir zaman geçtikten sonra sıradakilerin işi bitip benim işim de çalışınca sabırsızca beklediğim mydat.out dosyam oluşuyor. VI editörü ile mydat.out dosyasına bakarsak :
Beklediğimiz sonucu görüyoruz. Şimdi kodumuza tekrar dönelim. Temel bir C kullanıcısına yabancı gelen aşağıdaki satırlara bakalım:
HTML-Kodu:
// verilen proseslerin toplam sayısını bize size olarak dönmektedir
MPI_Comm_size( MPI_COMM_WORLD, &size );
// prosesin hangi bilgisayarda çalıştığı rank olarak dönmektedir
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
// sonuçları print ediyoruz
printf( “Hello world from process %d of %d \n", rank,size);
Yabancı fonksiyonlardan ilki olan Comm_size fonksiyonunu çağırıyoruz.
HTML-Kodu:
MPI_Comm_size( MPI_COMM_WORLD, &size );
Yukarıda da bahsettiğim gibi MPI_Comm_size fonksiyonu bize paralel makineye yüklediğimiz işin kaç bilgisayar tarafından çalıştırılacağını “size” değeri ile vermektedir. MPI_COMM_WORLD değişkeni ise çalıştığımız environmenti (çevre) vermekteyiz. Makinemiz bunu default çalışma parametresi almaktadır. Şimdi elimizde size değeri 4 makineye iş yüklediğimiz için 4 olarak bize dönmektedir. Sırada rank fonksiyonumuz var!
HTML-Kodu:
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
Rank fonksiyonu bize proseslerin MPI tarafından sıraya sokulduktan sonra hangi sırada olduğunu rank ile bize dönmektedir. En başta ki MPI_COMM_WORLD değerini de size fonksiyonunda olduğu gibi default olarak giriyoruz. MPI tarafından sıraya biz herhangi bir tanımlama yapmadığımız için ( prosesleri sıraya sokmak için ve bunların arasında etkileşimlere göre sıra önceliği tanımlayabileceğimiz fonksiyonlar vardır. Bunlar arasında MPI_Send, MPI_Recv, MPI_Ssend, MPI_Bsend, MPI_Buffer_attach, MPI_Rsend fonksiyonlarını sayabilirim bunları gelecek yazımda detaylı olarak anlatacağım ve örnek kodla açıklayacağım. Örnek olarak MPI_Recv fonksiyonu bir bilgisayardan mesaj aldığı zaman o mesajı gerçekleştirene kadar beklemektedir (eğer bunu kullanmazsak bir makinenin oluşturmadığı verilere ulaşmaya çalışmak hata döndürürdü).
Kolay Yötem : Job Script yazmadan çalıştırmak
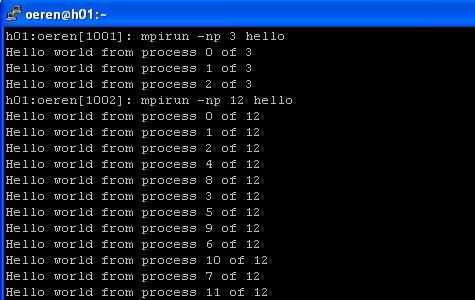
Yazıma girişte size bu job scripti yazmadan daha kolay bir şekilde bu programı çalıştırabileceğimizi söylemiştim (yine açıklayayım çoğu clusterlar buna izin vermemektedir ,PBS ve benzeri uygulamalar üzerinden programlar çalıştırılmaktadır). Şimdi gelelim kolay yönteme! Komut satırına mpirun np 3 hello yazıyoruz. Bunun anlamı şudur Bana 3 tane makine kullanarak hello uygulamasını çalıştır. Bu satırı yazdıktan sonra MPI aktif hale geliyor biz iş sırasını düzenlemediğimiz için MPI hangi prosesten önce cevap gelirse onları sıraya sokarak ekrana cevapları döndürüyor. Komutta eğer 3 yerine 12 yazarsak 12 node kullanarak çalıştırıyoruz. Gördüğünüz gibi her defasında ayrı bir sıra oluşuyor hangi işlemci daha hızlı cevabı gönderirse onun prosesi daha önce gözüküyor.
Özkan Eren'e tesekkurler!
___________________________________________________O____________________________________________________________
Asagida ki OpenMP anlatimi bir dergiden alintidir.
 İlk yazımın konusuna karar vermek her ne kadar güç olsa da, son günlerde gelişen işlemci teknolojilerinin ulaştığı çok çekirdekli mimariler ile birlikte paralel programlama olgusunun bilgisayar alanıyla gerek teorik, gerekse pratik olarak ilgilenen herkesin karşısına daha sık çıkacağını ve popülerliğini artırıp bir gereklilik halini alacağını düşündüğüm için bu konuyu irdeleyerek başlamak istedim. Kullanım alanlarına ve OpenMP’ye geçmeden önce konu hakkında kafamızda bir resim oluşması için çok fazla teorik detaya boğulmadan paralel hesaplama hakkında temel bilgileri sizlerle paylaşmak istiyorum.
İlk yazımın konusuna karar vermek her ne kadar güç olsa da, son günlerde gelişen işlemci teknolojilerinin ulaştığı çok çekirdekli mimariler ile birlikte paralel programlama olgusunun bilgisayar alanıyla gerek teorik, gerekse pratik olarak ilgilenen herkesin karşısına daha sık çıkacağını ve popülerliğini artırıp bir gereklilik halini alacağını düşündüğüm için bu konuyu irdeleyerek başlamak istedim. Kullanım alanlarına ve OpenMP’ye geçmeden önce konu hakkında kafamızda bir resim oluşması için çok fazla teorik detaya boğulmadan paralel hesaplama hakkında temel bilgileri sizlerle paylaşmak istiyorum.
Bilgisayar yazılımlarının geçmişine baktığımızda, yazılan programların sıralı hesaplamaya göre tasarlandığını görürüz. Detaylandıracak olursak:
-Yazılımlar tek çekirdekli bir işlemciye sahip bir bilgisayarda çalışmak üzere kodlanır
-Problem birbirinden ayrı, sıralı yönergeler serisine indirgenir
-Her yönerge bir diğerinin ardından işleme alınır
-Bir işlem süresinde sadece bir yönerge çalıştırılır.

Bunun yanı sıra, paralel hesaplama ya da paralel programlama mevcut çoklu hesaplama kaynaklarının eş zamanlı kullanılması üzerine kuruludur. Paralel hesaplamanın çalışma prensiplerine daha detaylı bakacak olursak:
-Çoklu işlemciler üzerinde çalışmak üzere tasarlanır
-Problem eş zamanlı çözülebilecek farklı alt parçalara bölünür
-Her parça kendi içerisinde sıralı yönergelere ayrılır
-Her parçadan yönergeler eş zamanlı olarak farklı işlemciler üzerinde çalıştırılır

Resimden de gördüğünüz üzere paralel hesaplama da aslında içerisinde sıralı hesaplamayı barındırıyor çünkü her yönerge için bir işlemciye sahip olmak gibi bir lüksümüz olmayacaktır J. İşlemci sayımız arttıkça her parçaya düşen yönerge sayısı da aynı oranda düşecektir.
OpenMP Nedir?
OpenMP sektörün önde gelen donanım ve yazılım üreticilerinin(Compaq, HP, IBM, Intel, Sun vs.) bir araya gelerek oluşturduğu bir uygulama arayüzüdür(API). OpenMP programcılara taşınabilir, ölçeklenebilir, paylaşılan bellek(shared memory) sistemini kullanan paralel uygulamalar yazmaları için bir model sağlar. OpenMP ile C, C++ ve FORTRAN dilleri ve UNIX ve Microsoft Windows gibi platformlar için uygulamalar geliştirebiliriz. Yazdığımız OpenMP yönergeleri herhangi bir değişiklik gerektirmeden bu platformlarda derlenebilir. Eğer kullanılan derleyici paralel programlamayı desteklemiyorsa OpenMP yönergeleri yorum olarak algılanır ve görmezden gelinir. Bu taşınabilirlik programcıyı birçok yükten kurtarır ve arka planda paralel programlama yapabilmek için gerekli derin problemlerle uğraşmak zorunda kalmayız, OpenMP bizi bu dertten kurtarıyor.OpenMP aslında bir multithreading uygulamasıdır ve tüm threadlerin ortak bir belleği paylaşması prensibi üzerine inşa edilmiştir. OpenMP paralelleştirme işlemini otomatik olarak yapmaz, programcı bunu açık olarak yapmalıdır ve tüm kontrol programcıdadır.
OpenMP fork-join(çatallaş-birleş) paralel çalışma metodunu kullanır. Ana thread, programcının kontrolünde paralelleştirilen bölgelere geldiğinde verilen direktiflere uygun olarak çatallaşır ve alt(köle) threadler yaratır. Yapılacak iş bu threadlere bölünerek eş zamanlı olarak çalıştırılır. Tüm threadler yapacağı işi bitirip paralel bölgenin sonuna geldiğinde senkronize olup ölürler ve yalnızca ana thread çalışmaya devam eder.

Birazda Uygulama
Temel bilgileri edindiğimize göre giriş seviyesinde OpenMP komutlarına göz atabiliriz. Uygulama örneklerimizde C/C++ dillerini kullanacağız. Öncelikle OpenMP komutlarının küçük/büyük harfe duyarlı olduğunu hatırlatmak isterim. OpenMP komutlarını kullanabilmek için kodumuza omp.h kütüphanesini dahil etmemiz(#include) gerekiyor. Genel kullanım kalıbı:
#pragma omp direktif_ismi [cümlecikler,..] (yeni satıra inilmeli)Parallel direktifi: Paralel bölge(parallel region) başlangıcını belirtir. Bir thread bu direktife geldiğinde threadlerden bir takım kurar ve ana thread olur. Ana thread de bu takımın bir parçasıdır ve 0 (sıfır) ile numaralandırılır. Paralel bölge başlangıcından itibaren kod çoğaltılarak threadler tarafından işletilir. Paralel bölge bitiminde ise uygulanan bir bariyer vardır ve bu bölgenin ötesine yalnızca ana thread geçebilir. Kaç adet thread yaratacağımızı belirlemenin birkaç yolu vardır:
-IF cümleciği yazmak (cümlecikler bölümüne)
-NUM_THREADS cümleciğine parametre vererek
-omp_set_num_threads() fonksiyonu ile paralel bölge oluşturmadan önce thread sayısını belirlemek. Örnek: omp_set_num_threads(8);
Örnek bir kod inceleyelim:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
#include main () { int nthreads, tid; /* Threadler çatallaşır ve bir takım oluşturur. Her thread kendine has tid değişkeninin bir kopyasını yaratır*/ #pragma omp parallel private(tid) { /* omp_get_thread_num() fonksiyonu ile thread numarası alınır ve yazdırılır */ tid = omp_get_thread_num(); printf("Thread = %d\n", tid); /* Bu if şartını sadece ana thread doğrulayıp çalıştıracaktır */ if (tid == 0) { nthreads = omp_get_num_threads(); /*Bu fonksiyon ile kaç adet thread yaratıldığı öğrenilir */ printf("Thread sayısı = %d\n", nthreads); } } /* Tüm threadler ana threadle birleşir ve sonlanırlar */ }
Kodun paralel kısmının başlangıcını incelersek aslında çok basit bir yapıya sahip olduğunu görürüz. Dikkat etmemiz gereken nokta pragma bloğunun “{“ işareti ile başlayıp “}” işareti ile sonlanmasıdır. Bu süslü parantezler arasında kalan bölge paralel bölgemizdir. Bir diğer nokta private cümleciğidir. Bu cümlecik parametre olarak aldığı değişkenin tüm threadlere “özel” olduğunu belirtir. Bu değişkenin her bir thread için diğer threadler tarafından ulaşılamayan özel kopyaları oluşturulur. Eğer shared deseydik bu değişken tüm threadler tarafından görülebilir olacaktı. omp_get_thread_num() fonksiyonu kod bloğunu çalıştıran threadin numarasını verir genellikle ana threade bazı işler yaptıracağımızda thread numarasını almak için kullanılır.omp_get_num_threads() komutu ise takımda kaç adet thread olduğunu döndürür. Bu kodu çalıştırdığımızda örneğin 4 adet threadimiz varsa paralel bölgemiz 4 kez işletilir.for direktifi ve döngüleri paralelleştirmek: Bu direktif sayesinde for döngülerimizi paralelleştirerek çalışma sürelerini kısaltıp performans kazanımı sağlayabiliriz. Bu direktifi kullanıyorsak döngümüzün içinde kontrolü döngü dışına atacak komutlardan kaçınmalıyız(örnek olarak: break komutu). for direktifini kullanırken bize yardımcı olacak cümlecikler şunlar:
- schedule: Döngümüzün threadler arasında nasıl bölüneceğini belirler. Bir yığın(chunk) parametresi ile döngü tekrarlarımızı kaç parçaya böleceğimizi belirleriz. STATIC parametresi ile kullanırsak yığınlarımız threadler arasında statik olarak dağıtılır. Yığın parametresi vermezsek mümkünse tekrarlar eşit olarak bölünecektir. DYNAMIC parametresi ile kullandığımızda verdiğimiz yığın parametresi threadlere dinamik olarak dağıtılır ve işini bitiren thread bir sonraki yığını yapmaya başlar.
- nowait: işini bitiren threadlerin diğer threadleri beklememesini sağlar.
Örnek Kod Parçası:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
for (i=0; i < 1000; i++) a[i] = b[i] = i * 1.0; chunk = 100; /*Paralel bölge başlangıcı*/ #pragma omp parallel shared(a,b,c,chunk) private(i) { #pragma omp for schedule(dynamic,chunk) nowait for (i=0; i < N; i++) c[i] = a[i] + b[i]; } /* Paralel bölge sonu */ }
Nasıl Derleriz?gcc derleyicimizde kodumuzu derlerken sonuna –fopenmp parametresini vermemiz yeterli olacaktır.
Paralel programlama ve OpenMP konularının her biri başlı başına derin ve tamamını bu yazımda aktaramayacağım kadar geniş konular. Bu yüzden ufakta olsa bu konulara bir giriş yaparak bilenlere hatırlatmak, daha önce duymamış olanlara ise farklı bir pencere açabilecek bu konuları tanıtmakla yetineceğim. Yazımı sonlandırmadan önce sizlerle çok ilginç ve önemli iki projeyi paylaşmak istiyorum. Bunlar dünya çapında yürütülen paralel hesaplama projelerinden SETI@Home ve Folding@Home. Bu iki projede de çok kompleks ve tek bir bilgisayarda yapılmaya kalkıldığında milyonlarca yıl sürebilecek hesaplamalar parçalara ayrılıp internet ağı aracılığıyla yüz binlerce gönüllü tarafından kendi bilgisayarlarında setler halinde yapılıp projeye yollanıyor. Bu şekilde muazzam bir işlemci gücüne ulaşılarak imkânsız gibi görünen hesaplamalar mümkün hale geliyor. SETI@Home projesi uzaydan gelen sinyalleri analiz ederek dünya dışı akıllı yaşam formu bulmayı amaçlayan bilimsel bir deney. Folding@Home projesi ise birçok kanser türü ve Alzheimer ve Parkinson gibi hastalıklara tıbbi ve genetik çözümler üretebilmek için proteinleri moleküler olarak incelemeyi amaçlıyor. Özellikle Folding@Home projesinin ilginizi çekebileceğine inanıyorum. Gelecek yazılarda görüşmek üzere.
OpenMP ile ilgili daha detaylı bilgi almak isteyenler için: https://computing.llnl.gov/tutorials/openMP/SETI@Home projesinin web adresi: http://setiathome.berkeley.edu/index.php
Folding@Home projesinin web adresi: http://folding.stanford.edu/
Yararlanılan Kaynaklar:
https://computing.llnl.gov/tutorials/openMP/
https://computing.llnl.gov/tutorials/parallel_comp/
http://en.wikipedia.org/wiki/Parallel_computing
http://en.wikipedia.org/wiki/OpenMP
Volkan DEMİRCAN'a tesekkurler!
-
Bu hafta, yaz icin 2 ayik, staj kabulu aldim ve bir paperdaki(link) algoritmalari OpenMP, PCL, OpenCV kutuphaneleri ve C++ dili kullanarak implement etmem istendi :) OpenMP calismaya baslamistim ki, arastirirken 2010 yilinda acilmis bu guzel konu da karsima cikti turkce olarak ^_^ Hem up olsun, guzel konu ve teknoloji hem de ben de video paylasayim dedim yeni konu acmadan.
Harika bir video serisi:
https://www.youtube.com/playlist?list=PLLX-Q6B8xqZ8n8bwjGdzBJ25X2utwnoEG
Bu da guzel bir kitap:
-
siiteye ayraç.




